
■ニュースメディア
■ニュースタイトル
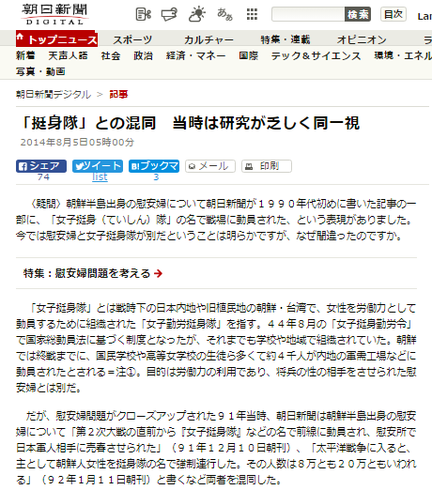
「『挺身隊』との混同 当時は研究が乏しく同一視 」にも検索回避メタタグ
■ニュース掲載・報道日
2018年9月4日発覚
■フェイク理由・ソースURL・その他
朝日新聞検索逃れメタタグ、日本語の挺身隊との混同記事にまだ残っていた!しかしWayback Machineで見ると2014年8月5日公開時には入ってない。どうやら2017年9月10日以降に挿入されたらしい。公開時の作業漏れで説明できるのか?しかも2019年4月30日で公開終了する設定に!これも後から加えた設定だ!(山岡鉄秀氏Twitter)
朝日新聞検索逃れメタタグ、日本語の挺身隊との混同記事にまだ残っていた!しかしWayback Machineで見ると2014年8月5日公開時には入ってない。どうやら2017年9月10日以降に挿入されたらしい。公開時の作業漏れで説明できるのか?しかも2019年4月30日で公開終了する設定に!これも後から加えた設定だ! pic.twitter.com/VMTAkC6ucX
— 山岡鉄秀 (@jcn92977110) September 4, 2018
■検証記事
----------------SEMリサーチ 2015.1.8
METAタグ活用完全ガイド noindex nofollow noarchive unavailable_after など使い方まとめ
検索エンジンのクローラの動作や行動を制御するためのロボット排除プロトコル(REP、Robots Exclusion Protocol)の中でも、robot meta タグを用いた方法の紹介です。2015年1月1日時点でサポートされているものを紹介しています。 nositelinkssearchbox などSEO担当者に関連するMETA要素も含んでいます。
以下、基本的な知識と、noindex, nofollow, nositelinkssearchbox, notranslate, noarchive, nocache, nosnippet, noimageindex, noodp, unavailable_after について個々のMETAタグの機能と役割に加えて、適宜注意事項も記載しています。

noindex:検索結果で対象ページを非表示にする
noindex は、対象ウェブページを検索結果で非表示にします。厳密に説明すると、「クローラは対象ウェブページを巡回して、インデックス(データベース)に格納するが、検索結果には表示しないようにする」という意味になります。
つまり noindex は文字通り「非表示」にするだけでクロール自体はされます。もしクロール自体を拒否したい場合は、robots.txt で disallow (クロール拒否)の指示を行わなければなりません。
例1) 全てのクローラに noindex を指示
<meta name="robots" content="noindex">
(全てのクローラに対して、対象ページを検索結果に表示しないように指示)
例2) Googlebot に noindex を指示
<meta name="googlebot" content="noindex">

コメントをお書きください